
Unnesting Firebase Events Table
Get major cost savings from BigQuery by having a good data model on Firebase events table

In the previous article, we created some functions to query events table and it helped to make it easier to query.
Firebase Events Table

In our previous post, we explored the process of exporting data to BigQuery. Now, it's time to delve into the wealth of insights stored in this extensive table containing all your user events and detailed user information. While a comprehensive explanation of each column is available
Even though these functions make our lives easier, we can make it even better. get_param and get_prop parameters require you to type a lot of characters, and also you have to remember the data type every time. Also, since event_params contains all the other parameters, querying it becomes very expensive.
To avoid this problem, I'll recommend a new data model to simplify querying.
Problem 1 - Too many characters
To be able to get a single parameter, let's say level, I have to type these all the time:
fn.get_param_int(event_params, 'level') as levelThe problems here are:
I have to repeat
fn.get_param_intfor every parameterI have to repeat
event_paramsevery timeI have to know the data type of the level parameter (in this example
int)
Problem 2- Query costs
BigQuery charges per data scanned, and it costs a lot every time we access event_params.
To understand why, let's check an example event_params row:
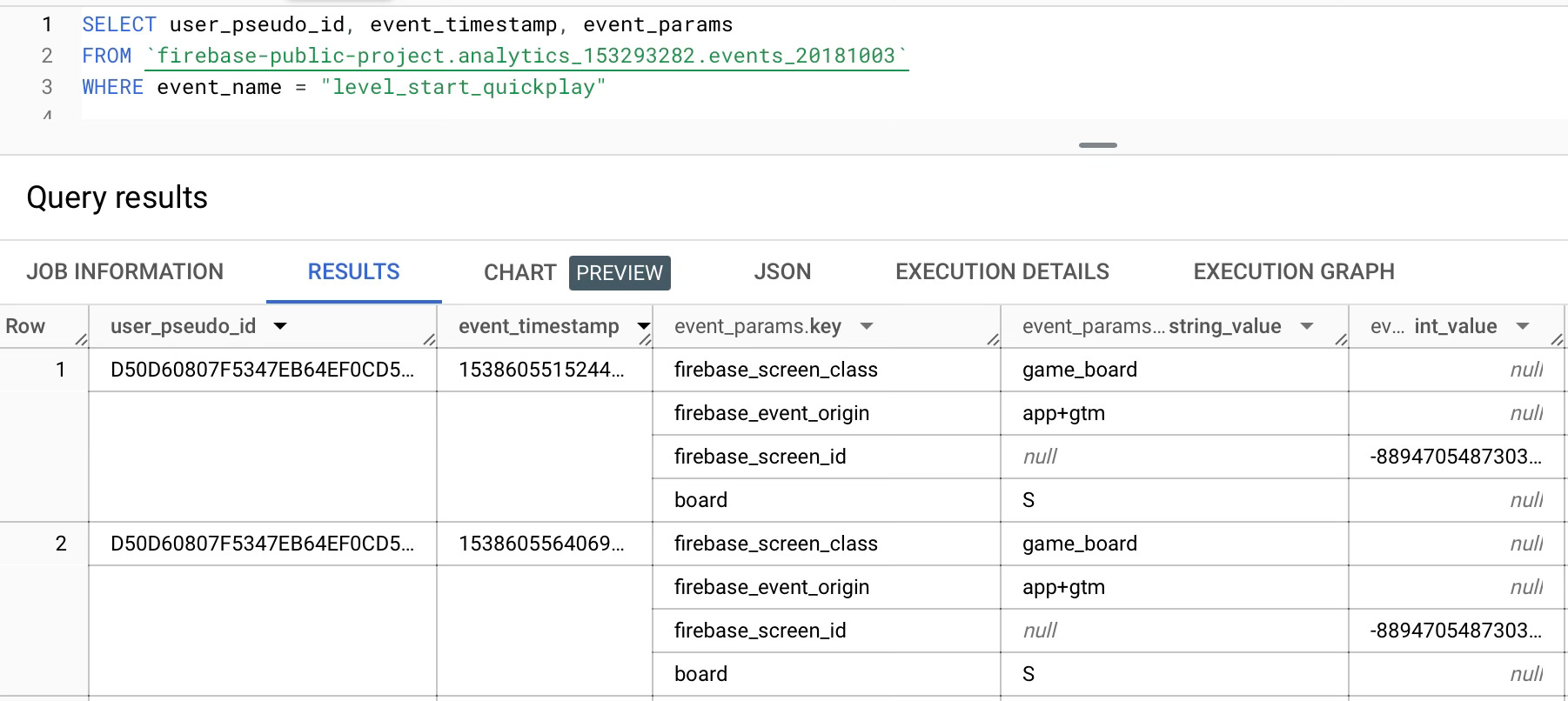
Here, even though the client sends only 1 parameter, board, Firebase automatically adds 3 other parameters.
Let's calculate the data size BigQuery scans only to access the parameter “board”.
Since event_params is an array, we have to scan all the details in the array (there are very small optimizations behind, but for now I ignore them)
key column:
firebase_screen_class: 21 characters
firebase_event_origin: 21 characters
firebase_screen_id: 18 characters
board: 5 characters
total: 65 characters
values.string_value column
game_board: 10 characters
app+gtm: 7 characters
S: 1 character
total: 18 characters
So just to get a single character, `S`, BigQuery had to scan 65 + 18 = 83 characters. So this query could be 83 times cheaper!
To make this calculation, I already ignored the int and float value columns.
Also, this event has only 4 parameters, but most have many more parameters.
So imagine there are 15 parameters with an average of 15 characters. It would mean scanning 225 characters just for a single character! It’s a crazy amount of savings. (1/225 = Only 0.4% of the total scans)
Solution 1 - Unnested Events Table
So how can we solve this problem?
If we had a column named board, it would be great, right?
Imagine all the parameters are already a column in the events table, and BigQuery autocompletes your query, and also it costs much much less...
In this approach, we run an unnesting query periodically, so this query only runs once and then the rest of the queries are done on the new table.
An example unnested events query would be like:
CREATE TABLE events.events
PARTITION BY dt CLUSTER BY event_name
AS
SELECT
app_info.id AS app,
platform,
PARSE_DATE('%Y%m%d', event_date) AS dt,
TIMESTAMP_MICROS(event_timestamp) AS ts,
TIMESTAMP_MICROS(user_first_touch_timestamp) AS install_ts,
user_pseudo_id,
user_id,
lower(event_name) as event_name,
app_info.version AS app_version,
device.advertising_id,
device.vendor_id,
geo.country AS geo_country,
device.category AS device_type,
device.mobile_brand_name AS device_brand,
device.mobile_marketing_name AS device_marketing_name,
device.mobile_model_name AS device_model,
device.mobile_os_hardware_model AS device_hardware_model,
device.language AS device_language,
CASE lower(device.is_limited_ad_tracking)
WHEN 'yes' THEN True
WHEN 'no' THEN False
END AS device_limited_ad_tracking,
device.operating_system AS device_os,
device.operating_system_version AS device_os_version,
event_server_timestamp_offset / 1000 AS event_server_timestamp_offset,
device.time_zone_offset_seconds / 3600 AS device_time_zone_offset_seconds,
func.get_param_str(event_params, 'firebase_screen') AS screen,
func.get_param_str(event_params, 'firebase_screen_class') AS screen_class,
func.get_param_int(event_params, 'ga_session_id') AS session_id,
func.get_param_int(event_params, 'ga_session_number') AS session_number,
func.get_param_int(event_params, 'board') AS board,
FROM `firebase-public-project.analytics_153293282.events_*`In this query, you can add all your event parameters and user properties, then schedule it to run once a day. You will have a very clean events table and it will be much cheaper to query.
However, this approach has a problem. As your events evolve and you send more and more parameters, it will be hard to maintain this table.
For every new parameter, you have to create a new column like this, first:
ALTER TABLE events
ADD COLUMN new_column INT64;If you are late adding the new parameters to the table, you have to backfill it for the previous days.
Solution 2- Json Events Table
In previous years, BigQuery introduced a relatively new datatype: JSON.
JSON datatype gives flexibility in terms of new keys/parameters, and also it's stored as columnar in the storage layer. So, if you access a parameter in a JSON field, it would still be very cheap compared to the event_params column.
Here, I come up with another function:
CREATE OR REPLACE FUNCTION `fn.event_params_to_json`(
event_params ARRAY<STRUCT<
key STRING,
value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64>
>>
)
AS ((
with t1 as
(
select
array_agg(p.key) as keys,
array_agg(coalesce(
p.value.string_value,
cast(p.value.int_value as string),
cast(coalesce(p.value.double_value, p.value.float_value) as string)
)) as vals
from unnest(event_params) as p
where key not in ("firebase_screen", "firebase_screen_class", "ga_session_id", "ga_session_number", "engaged_session_event", "engagement_time_msec", "firebase_event_origin", "firebase_previous_id", "firebase_screen_id")
)
select case when array_length(keys) > 0 then json_object(keys, vals) end
from t1
));This function converts all the parameters to string and then creates a JSON object from them.
The reason I converted all of them to string is that BigQuery doesn't allow creating a JSON object with different data types.
At the end, you'll have a dictionary like:
{
"firebase_screen_class": "game_board",
"firebase_event_origin": "app+gtm",
"firebase_screen_id": "-8894705......",
"board": "S"
}To create a JSON event_params column, you can use this query:
CREATE TABLE events.events_json
PARTITION BY dt CLUSTER BY event_name AS
SELECT
app_info.id as app,
platform,
PARSE_DATE('%Y%m%d', event_date) as dt,
TIMESTAMP_MICROS(event_timestamp) as ts,
TIMESTAMP_MICROS(user_first_touch_timestamp) as user_first_touch_ts,
user_pseudo_id,
user_id,
lower(event_name) as event_name,
fn.parse_version(app_info.version) as app_version,
fn.event_params_to_json(event_params) as ep,
FROM `firebase-public-project.analytics_153293282.events_*`And then, you can use this query to access the board parameter:
SELECT lax_string(ep.board) as board
FROM events.events_jsonWith this query, we gained flexibility but lost query comfort. Now, we have to type more characters. To fix it, I recommend creating a view on top of this table, so it will be very similar to solution 1, but also flexible. Views don't occupy space in the storage but use the underlying tables to retrieve data.
To create the view, you can use this query:
CREATE OR REPLACE VIEW events.events AS
SELECT
* except(up, ep),
lax_string(ep.board) as board,
FROM events.events_jsonSo every time you query the table events.events, it actually goes through events.events_json table and retrieves the recent data. In the case there is a new parameter, the only thing you need to do is add it to events.events view.
Running this pipeline on production
Event tables are incremental tables and older days' data is not updated. If you're using intraday, it doesn't backfill older data, if you're using batch export, every day it updates the last 3 days of data. Based on my personal experience, added data to previous days tends to be ~1-2% of the total events, so you might choose to ignore it.
Since data is only added incrementally, you don't have to create the whole events table every day, and instead run incremental pipelines. While incremental strategies can go a long way, it is pretty simple for our article: you can just read yesterday’s data and append it to the current table. This way, your ETL costs will decrease significantly, and your ETL process will be completed much faster.
I only shared the CREATE queries above to keep it short, but in this repo, you can find how to make them incremental using Bruin.
Running Bruin
To run the pipeline steps in the right order, you need what’s called an “orchestrator”. Bruin is an open-source orchestrator that allows you to define your data pipelines as a collection of assets, and run them in your data warehouse.
You can install Bruin CLI by following the instructions here.
If you already have Bruin CLI, you can use the command below in the terminal to get a fresh start and it will automatically create a starter template for you. You can update this pipeline according to your needs and use it in the production.
brew tap bruin-data/tap
bruin init firebaseAs a result of this command, you will have a fully-prepared production-ready data pipeline based on our articles, applying the best practices of managing Firebase data.
If you have questions about this article or running Bruin pipelines, join our Slack community.
In the next article, I'll explain how to create a daily summary table and we will create our first dashboard on Looker Studio. You can subscribe to this newsletter to get updated about the next article.