

In our previous post, we explored the process of exporting data to BigQuery. Now, it's time to delve into the wealth of insights stored in this extensive table containing all your user events and detailed user information.
While a comprehensive explanation of each column is available here, this post will focus on making the table more accessible.
Accessing Firebase Demo Project
Let's kick things off with the Firebase demo project. If you already have a project, you don’t need to follow this step, you can just jump to the next topic below.
The demo dataset resides in the firebase-public-project, and you can add it to your workspace with a simple click on the + ADD button near above the data catalog.
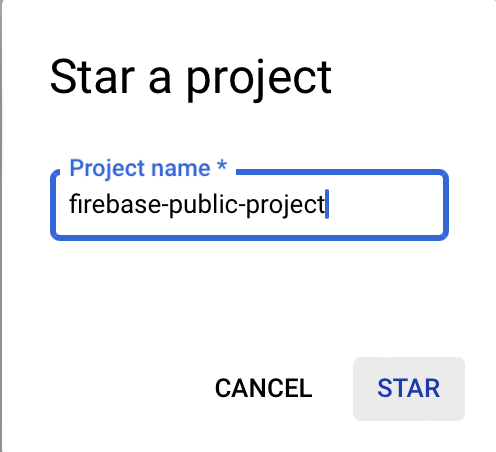
Select the Star a project by name option, and type firebase-public project in the window that appears.
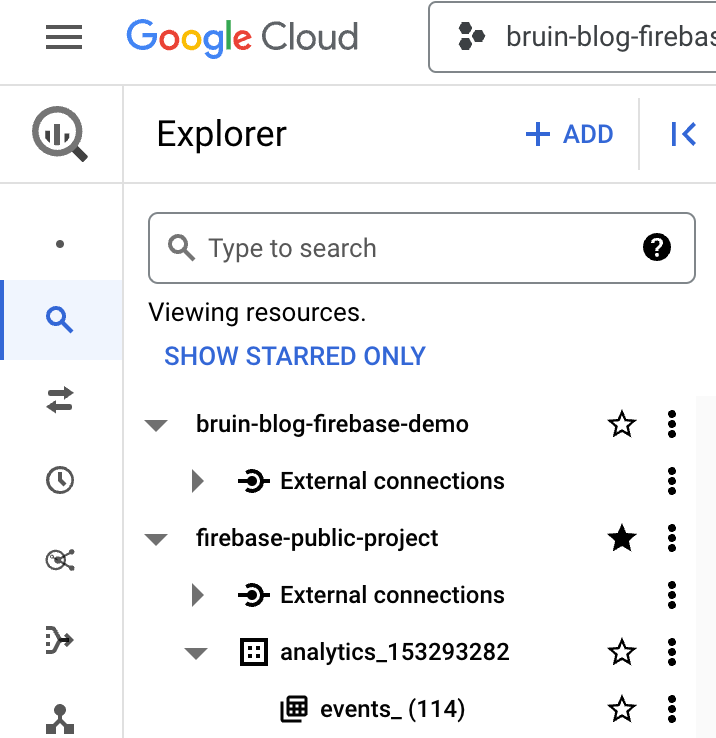
Upon clicking 'Star,' you'll find this dataset conveniently located in the left pane.
Understanding Events Table
Once you start exporting your data to BigQuery, you'll encounter a very wide table in BigQuery which is hard to understand and contains too much information.
Depending on your export settings, Firebase exports events in 2 names:
events_
events_intraday_
These tables are sharded tables, and generates a table for each day. For example, for 30 September 2023, the table name will be events_20230930.
Let's write our first query to see the event counts on a specific day, "2018-10-03".
SELECT
event_name,
count(*) as event_cnt,
count(distinct user_pseudo_id) as user_cnt,
count(*) / count(distinct user_pseudo_id) as event_per_user
FROM `firebase-public-project.analytics_153293282.events_20181003`
GROUP BY 1
ORDER BY 2 desc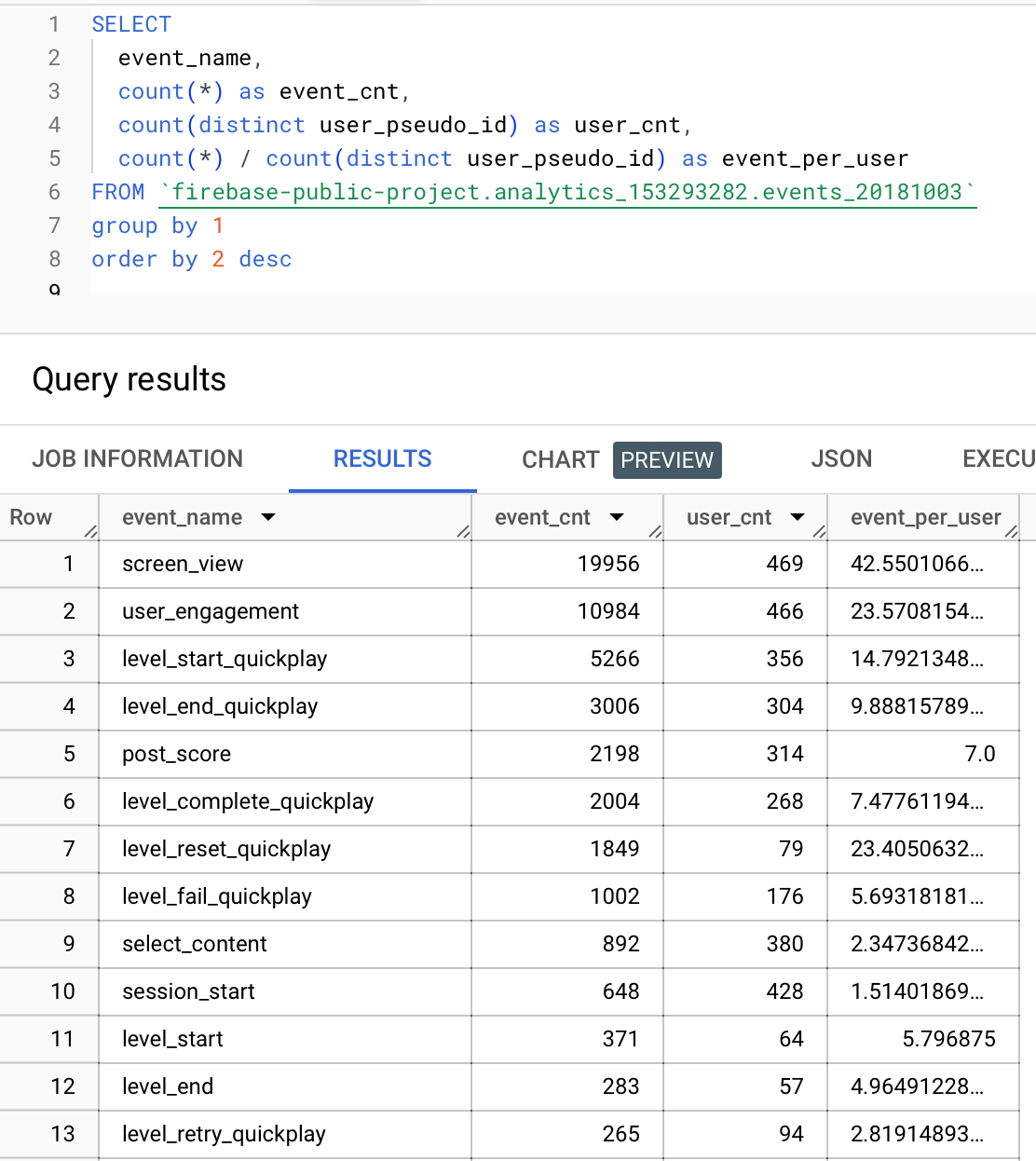
Firebase triggers some events like screen_view, user_engagement automatically, so if you haven't triggered any of them, you don't need to get worried.
Working with Event Timestamp Column
If you preview the events table, the first thing you’ll see is, event_timestamp is an integer, and not easy to understand.
To convert it to a timestamp, you can use the TIMESTAMP_MICROS function.
Let's find hourly level starts in our game. To understand how timestamp_trunc function works, you can check the documentation.
SELECT
timestamp_trunc(timestamp_micros(event_timestamp), hour) as hour,
count(*) as events
FROM `firebase-public-project.analytics_153293282.events_20181003`
GROUP BY 1
ORDER BY 1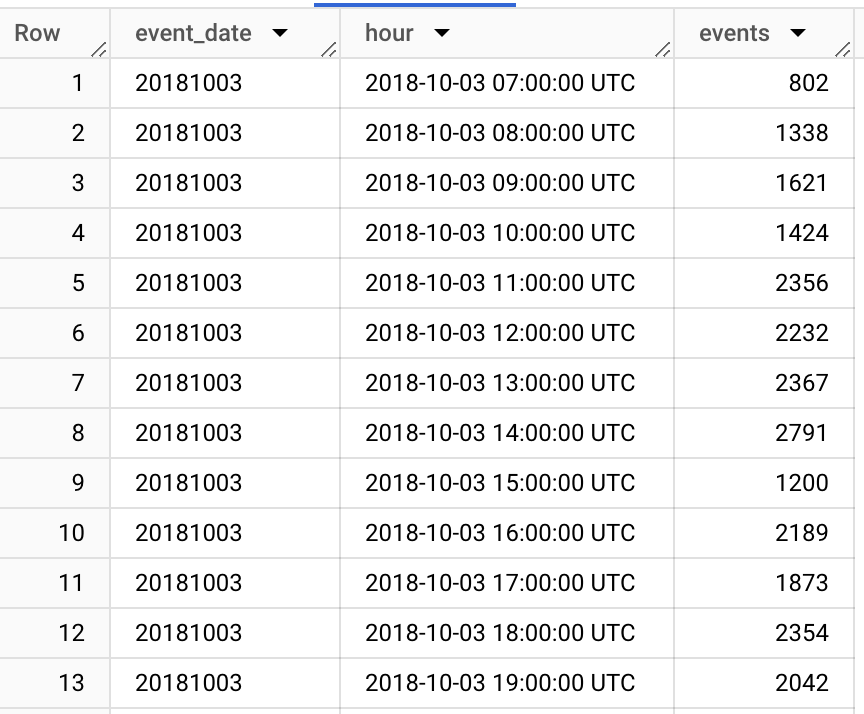
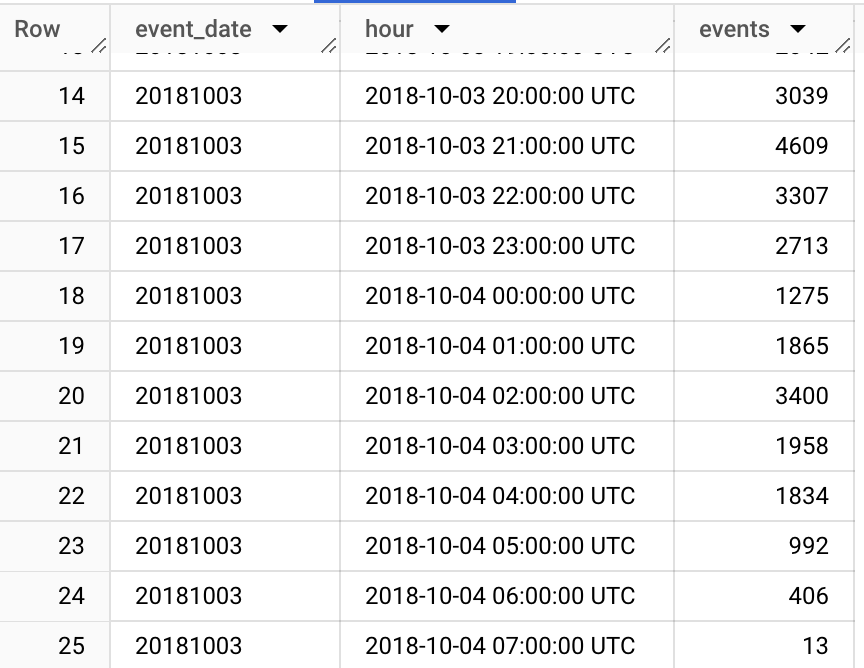
As you can see here, even though we queried the data for 2018-10-03, we got data from 7:00 AM to the next day until 7:00 AM. It happens due to the reporting time zone in Google Analytics settings. There always will be a difference between event_date and event_timestamp, but to minimize it you can choose UTC as time zone.
Querying Events, Event Params and User Properties
Let's focus on level_start_quickplay event and see some of the events and parameters.
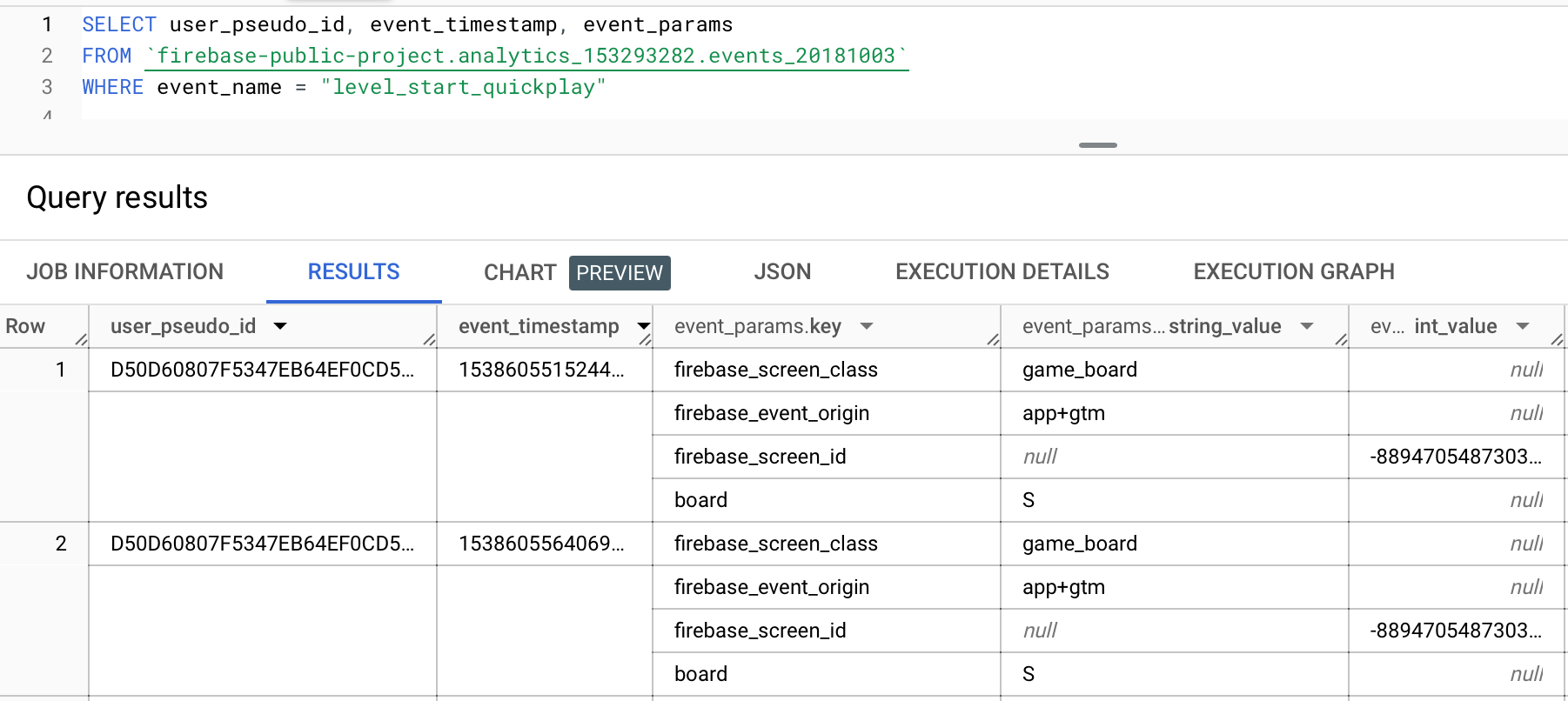
There is a `board` parameter in event_params, and the value is `S`. It keeps the board size value for the played level.
Let's count level starts per board, but event_params is an array. How do we access it?
For both event_params and user_properties, we can use this code to access the parameters:
(select value.{PARAMETER_TYPE}_value from unnest(event_params) where key = "{PARAMETER_NAME}")So to access the parameter, let's use it in the query and count it:
SELECT
(select value.string_value from unnest(event_params) where key = "board") as board,
count(*) as cnt
FROM `firebase-public-project.analytics_153293282.events_20181003`
WHERE event_name = "level_start_quickplay"
GROUP BY 1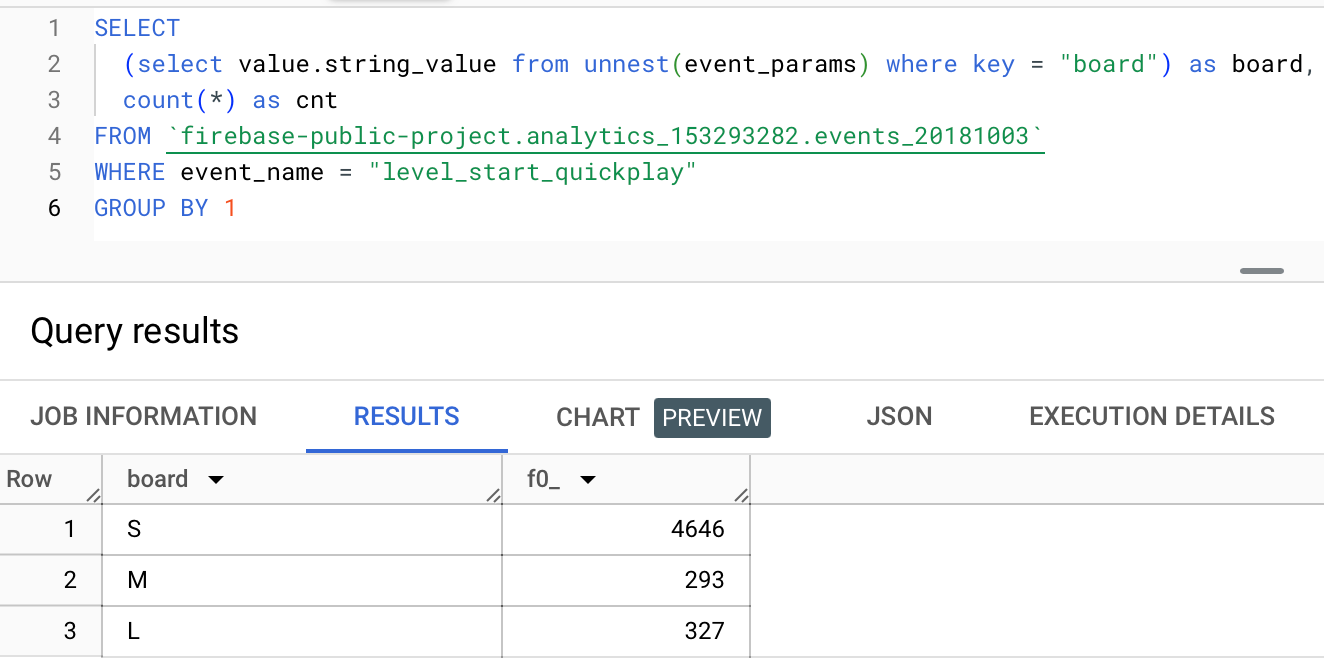
Get Param Functions
As you want to include more and more parameters, writing this query will be very annoying.
For that purpose, I created some functions for you. First, I recommend you to create a dataset called fn and store all the functions in that dataset. Don't forget to choose the same region as the events tables region for this dataset.
CREATE OR REPLACE FUNCTION fn.get_param_str(event_params ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64>>>, param_key STRING) AS
((
SELECT
COALESCE(
value.string_value,
CAST(value.int_value as string),
CAST(value.float_value as string),
CAST(value.double_value as string)
)
FROM UNNEST(event_params) WHERE key = param_key
));
CREATE OR REPLACE FUNCTION fn.get_param_int(event_params ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64>>>, param_key STRING) AS
((
SELECT
COALESCE(
value.int_value,
SAFE_CAST(value.float_value as int64),
SAFE_CAST(value.double_value as int64),
SAFE_CAST(value.string_value as int64)
)
FROM UNNEST(event_params) WHERE key = param_key
));
CREATE OR REPLACE FUNCTION fn.get_param_float(event_params ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64>>>, param_key STRING) AS
((
SELECT
COALESCE(
value.float_value,
value.double_value,
CAST(value.int_value as FLOAT64),
SAFE_CAST(value.string_value as FLOAT64)
)
FROM UNNEST(event_params) WHERE key = param_key
));
CREATE OR REPLACE FUNCTION `fn.get_param_bool`(event_params ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64>>>, param_key STRING) AS (
SAFE_CAST(fn.get_param_int(event_params, param_key) as bool)
);After creating these functions, you can rewrite your query as:
SELECT
fn.get_param_str(event_params, "board") as board,
count(*) as cnt
FROM `firebase-public-project.analytics_153293282.events_20181003`
WHERE event_name = "level_start_quickplay"
GROUP BY 1Let’s query post_score event with parameters:
First, to find the parameters, let’s check the table without manipulation:
SELECT
user_pseudo_id,
timestamp_micros(event_timestamp) as ts,
event_params
FROM `firebase-public-project.analytics_153293282.events_20181003`
WHERE event_name = "post_score"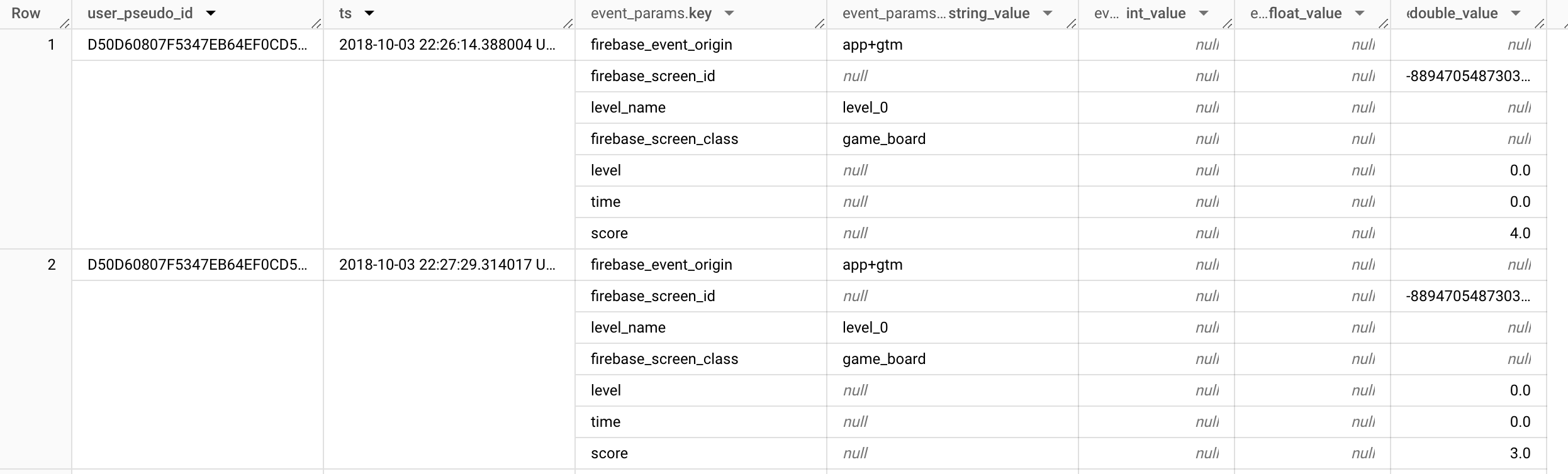
Here, we can see that there are 4 parameters relevant to the event.
level_name (string)
level (double)
time (double)
score (double)
If we use our functions to unnest the parameters, the query looks like that. Since BigQuery doesn’t have a double datatype, doubles are queried as floats:
SELECT
user_pseudo_id,
timestamp_micros(event_timestamp) as ts,
fn.get_param_str(event_params, "level_name") as level_name,
fn.get_param_float(event_params, "level") as level,
fn.get_param_float(event_params, "time") as time,
fn.get_param_float(event_params, "score") as score,
FROM `firebase-public-project.analytics_153293282.events_20181003`
WHERE event_name = "post_score"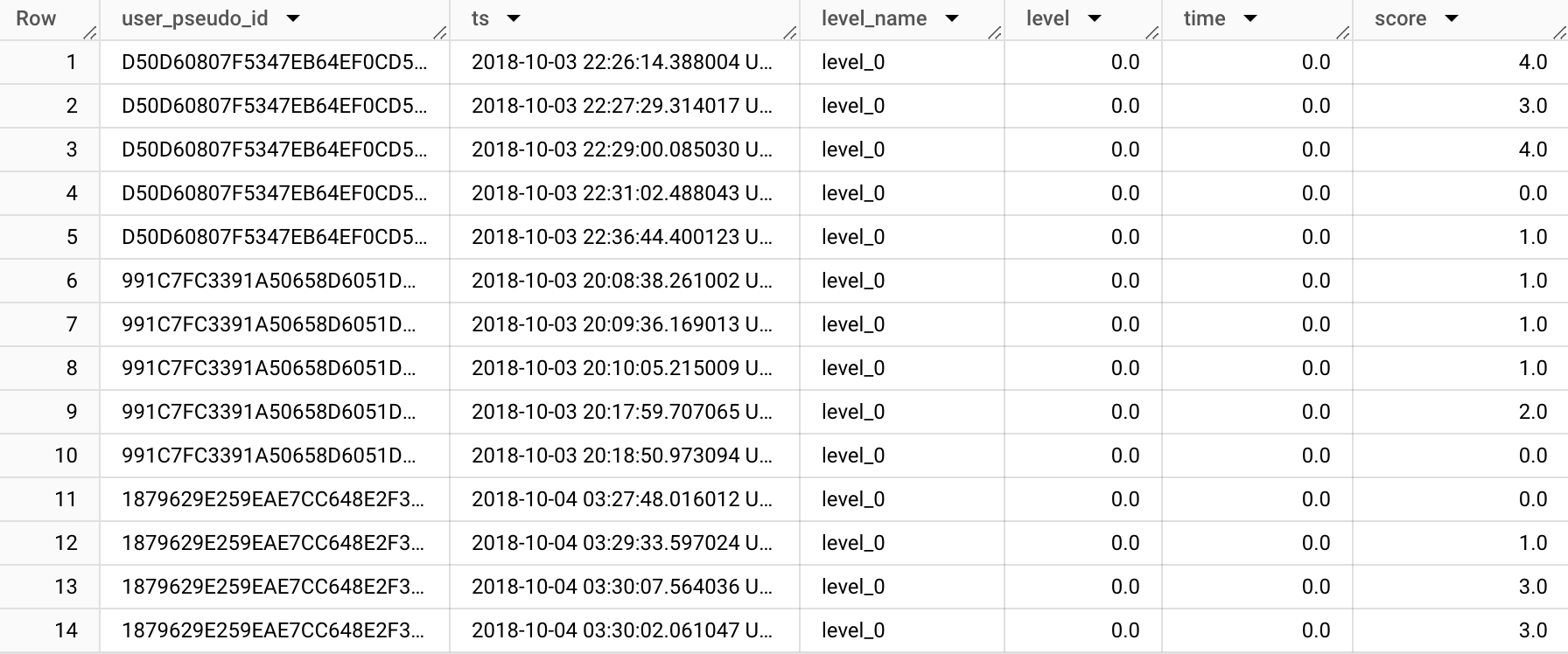
Even though parameters are sent as double/float, it looks like they indeed are integers. Let’s verify it by checking all the values:
SELECT
fn.get_param_float(event_params, "score") as score,
count(*)
FROM `firebase-public-project.analytics_153293282.events_20181003`
WHERE event_name = "post_score"
group by 1
order by 1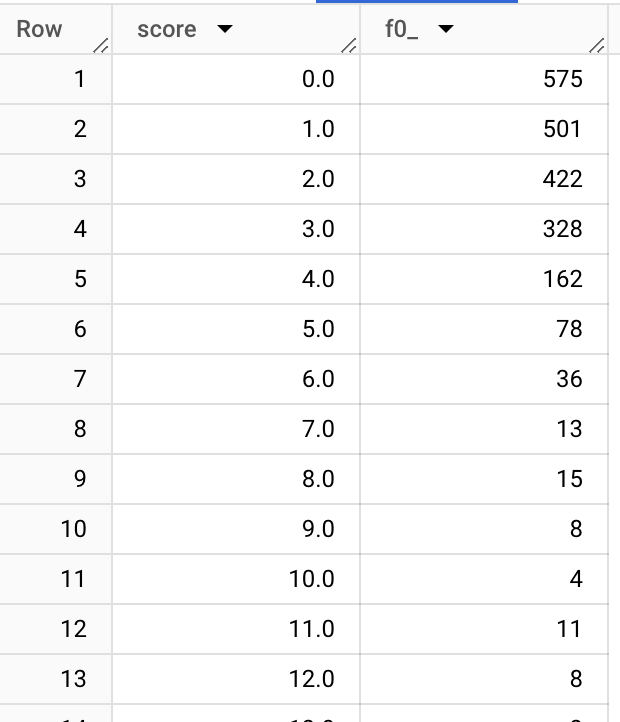
As suspected, all the rows are actually integers. If we do the same check for level and time, we see that they are also integers.
So let’s rewrite our query:
SELECT
user_pseudo_id,
timestamp_micros(event_timestamp) as ts,
fn.get_param_str(event_params, "level_name") as level_name,
fn.get_param_int(event_params, "level") as level,
fn.get_param_int(event_params, "time") as time,
fn.get_param_int(event_params, "score") as score,
FROM `firebase-public-project.analytics_153293282.events_20181003`
WHERE event_name = "post_score"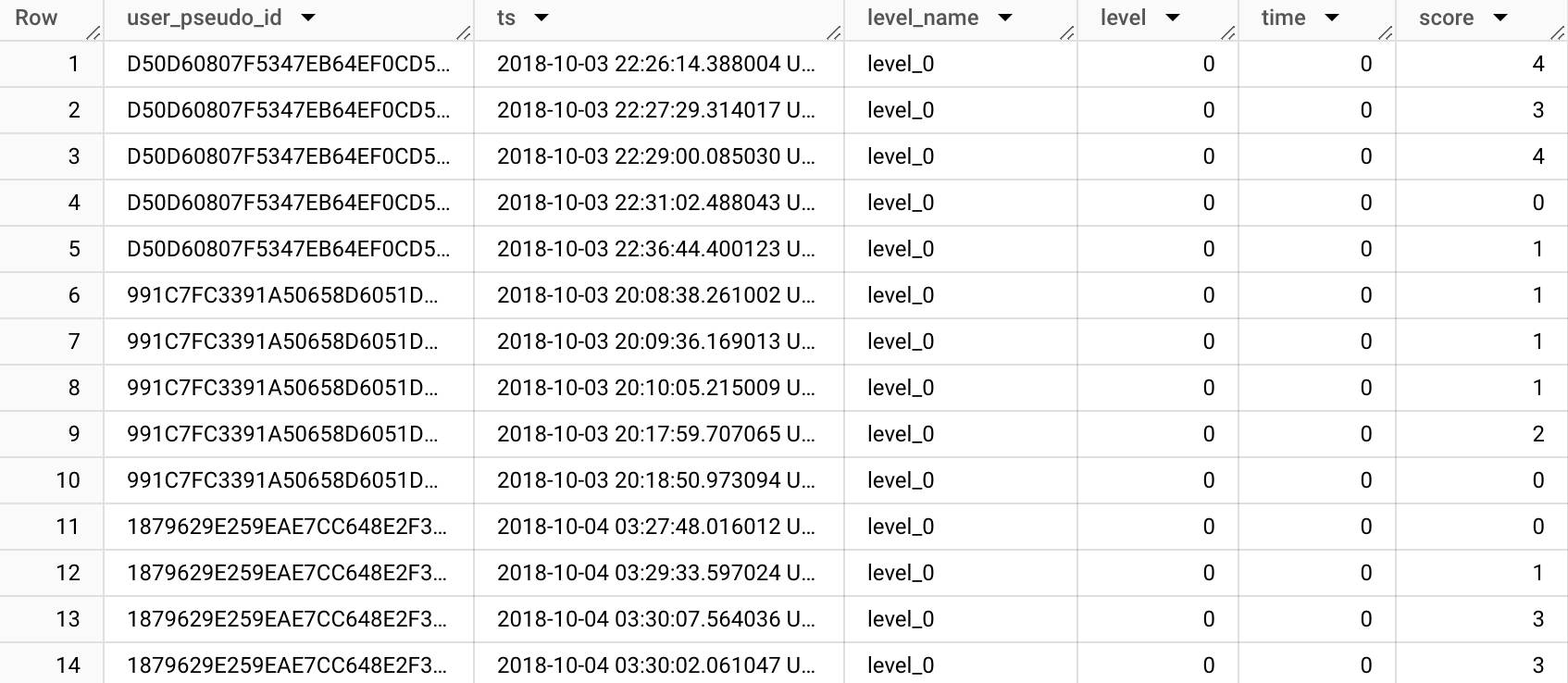
We get the same table, but with correct datatypes this time.
get_param_* and get_prop_* functions are automatically casting the data to the right data types, so you don’t have to cast them again.
Here is the code for get_prop functions:
CREATE OR REPLACE FUNCTION `fn.get_prop_str`(user_properties ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64, set_timestamp_micros INT64>>>, param_key STRING) AS (
(
SELECT
COALESCE(
value.string_value,
CAST(value.int_value as string),
CAST(value.float_value as string),
CAST(value.double_value as string)
)
FROM UNNEST(user_properties) WHERE key = param_key
)
);
CREATE OR REPLACE FUNCTION `fn.get_prop_int`(user_properties ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64, set_timestamp_micros INT64>>>, param_key STRING) AS (
(
SELECT
COALESCE(
value.int_value,
SAFE_CAST(value.float_value as int64),
SAFE_CAST(value.double_value as int64),
SAFE_CAST(value.string_value as int64)
)
FROM UNNEST(user_properties) WHERE key = param_key
)
);
CREATE OR REPLACE FUNCTION `fn.get_prop_bool`(user_properties ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64, set_timestamp_micros INT64>>>, param_key STRING) AS
(
COALESCE(
SAFE_CAST(fn.get_prop_int(user_properties, param_key) as bool),
SAFE_CAST(fn.get_prop_str(user_properties, param_key) as bool)
)
);
CREATE OR REPLACE FUNCTION `fn.get_prop_double`(user_properties ARRAY<STRUCT<key STRING, value STRUCT<string_value STRING, int_value INT64, float_value FLOAT64, double_value FLOAT64, set_timestamp_micros INT64>>>, param_key STRING) AS (
(
SELECT
COALESCE(
value.double_value,
value.float_value,
CAST(value.int_value as FLOAT64),
SAFE_CAST(value.string_value as FLOAT64)
)
FROM UNNEST(user_properties) WHERE key = param_key
)
);Querying multiple days
Until here, we only queried 1 day of data, specifically 2018-10-03.
What if we want to query multiple days?
BigQuery gives you a flexible way of querying sharded tables. You can just use `*` instead of the date in the table name, and you will be able to query all the dates:
SELECT
event_date,
count(*) as cnt,
avg(fn.get_param_int(event_params, "score")) as avg_score,
avg(fn.get_param_int(event_params, "level")) as avg_level
FROM `firebase-public-project.analytics_153293282.events_*`
WHERE event_name = "post_score"
GROUP BY 1
ORDER BY 1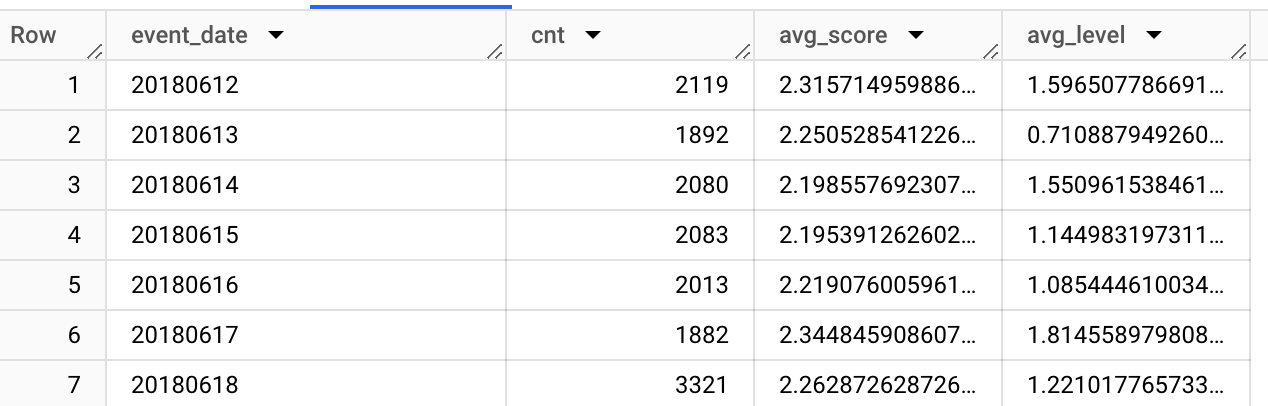
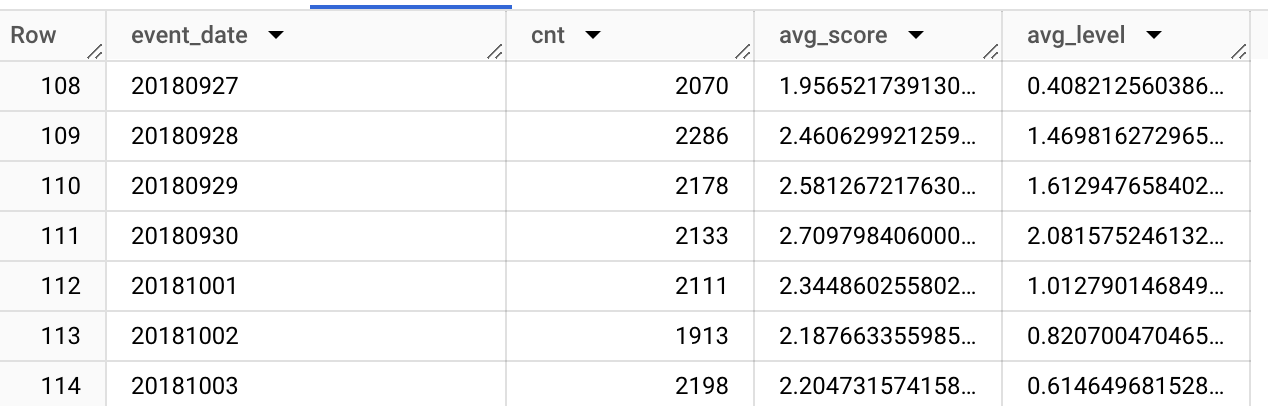
This query returns 114 rows, for days between 12 June and 3 October.
However, you might need only the days between instead of full data. It will be both cheaper since we scan less data, and also might be more useful for our analysis. In that case, we’re using _TABLE_SUFFIX to filter the dates:
SELECT
PARSE_DATE('%Y%m%d', event_date) as dt,
count(*) as cnt,
avg(fn.get_param_int(event_params, "score")) as avg_score,
avg(fn.get_param_int(event_params, "level")) as avg_level
FROM `firebase-public-project.analytics_153293282.events_*`
WHERE event_name = "post_score"
AND _TABLE_SUFFIX between '20180701' and '20180731'
GROUP BY 1
ORDER BY 1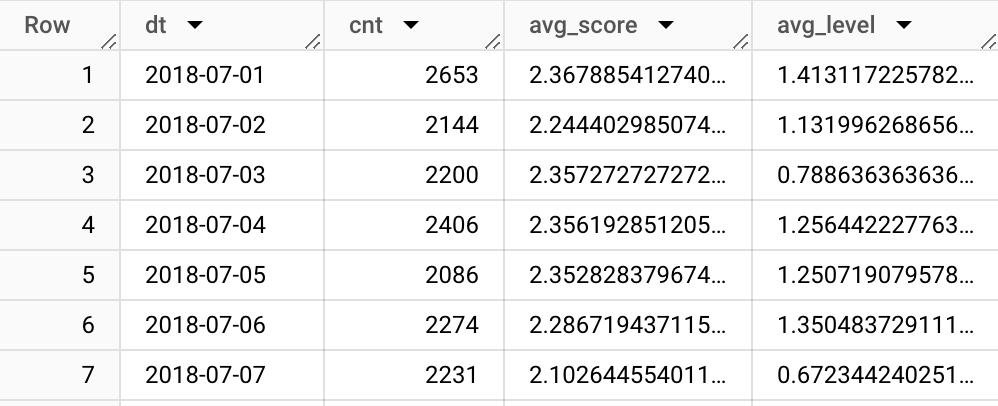
This query returns only July’s data which I need, also it costs much less compared to querying all data.
I made another change in that query as well, instead of using event_date, I used the PARSE_DATE function because event_date is stored as a string, and it’s both hard to read and also impossible to apply date operations. So by using parse_date, we converted it to date datatype.
Even though it’s much easier to query now, we still need to know of the parameters name, datatype, etc. In the next article we’ll transform this table to make it easier and cheaper to query.